Пакетная обработка данных с автоскейлингом вычислительных ресурсов
Реализовали в платформе обработку файлов пакетами с автоматическим масштабированием вычислительных ресурсов под нагрузку.
Задача и проблема
В компаниях, где регулярно обрабатывают большие объемы данных — например, изображения, видео, сканы, результаты расчетов или модели — задачи часто запускают по одной. Это замедляет работу, когда нужно обработать сразу десятки или сотни файлов.
При массовом запуске появляется другая проблема: нагрузка резко растет, и текущих вычислительных мощностей не хватает. Задачи выстраиваются в очередь, увеличивается время обработки. При этом держать инфраструктуру с запасом под пиковые нагрузки невыгодно — ресурсы простаивают.
В результате компании сталкиваются с выбором: либо медленная обработка данных, либо избыточные затраты на инфраструктуру.
Задача — настроить автоматизацию вычислений, упростить запуск задач для больших массивов данных и обеспечить гибкое управление нагрузкой.
Решение — пакетная обработка задач с автоскейлингом
Сделали пакетную обработку файлов с автоматическим управлением вычислительными ресурсами.
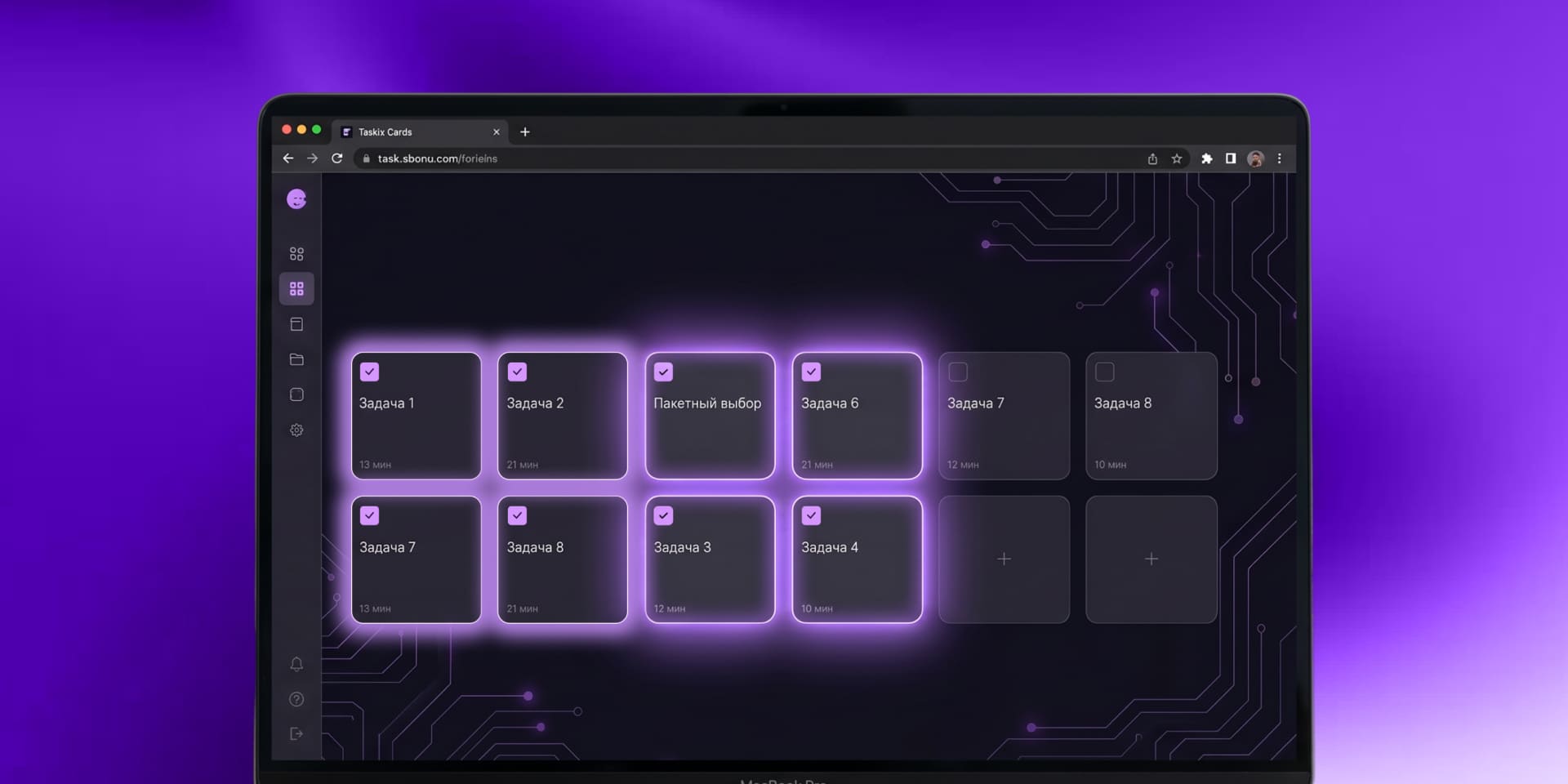
Мы реализовали механизм массового запуска задач: пользователь выбирает файлы из хранилища и отправляет их в обработку одним действием. Это упрощает работу с большими объемами и ускоряет получение результата
Обработка проходит на вычислительном кластере: система распределяет задачи между узлами и выполняет их параллельно. За счет этого сокращается общее время обработки и снижается нагрузка на локальную инфраструктуру.
Оптимизация вычислительных ресурсов
Ключевая часть решения — динамическое распределение ресурсов. При появлении задач система автоматически поднимает дополнительные вычислительные мощности, а после завершения обработки — отключает их.
Такой подход реализует автоскейлинг ресурсов и позволяет оптимизировать затраты: инфраструктура используется по фактической нагрузке, без избыточных мощностей.
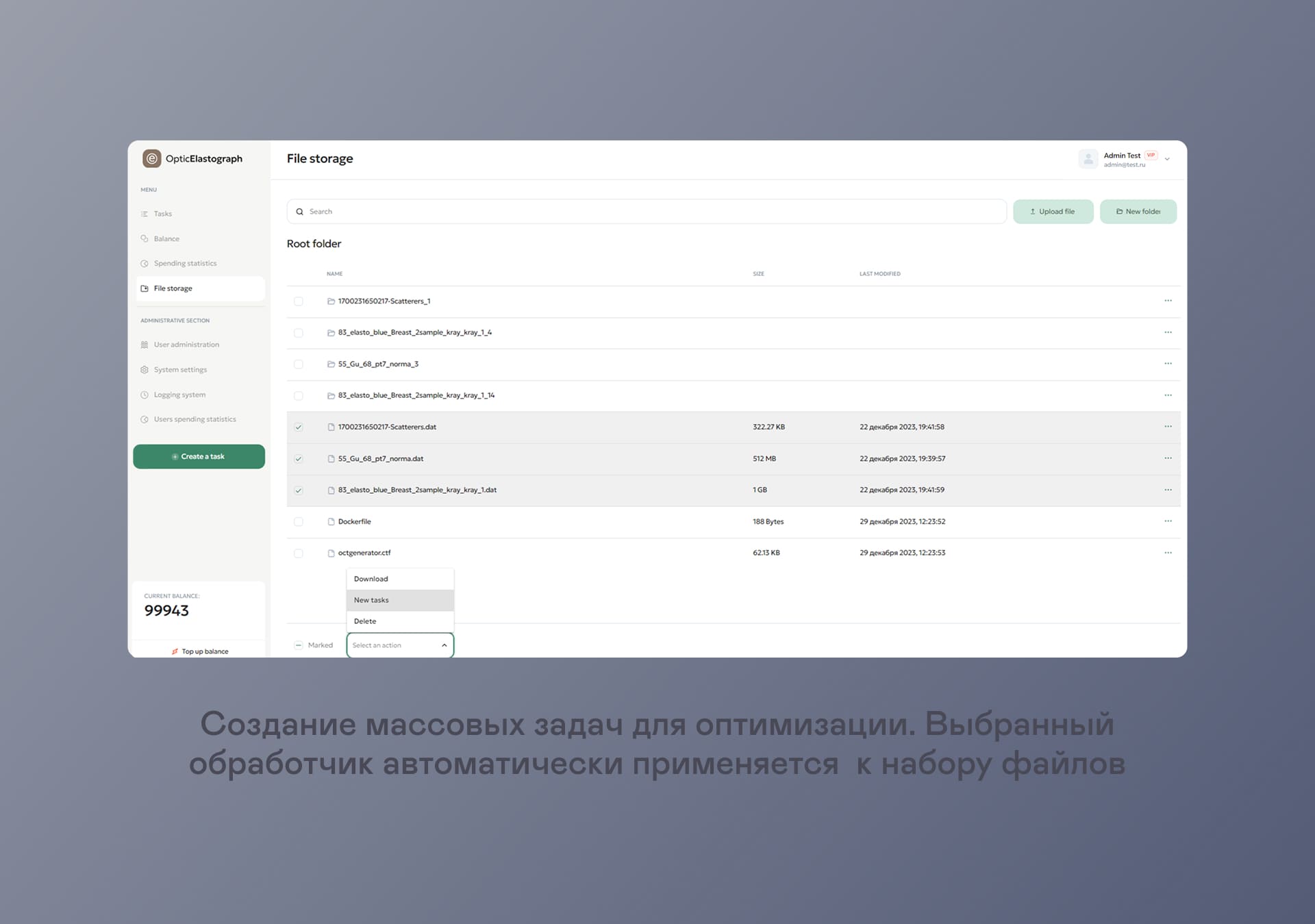
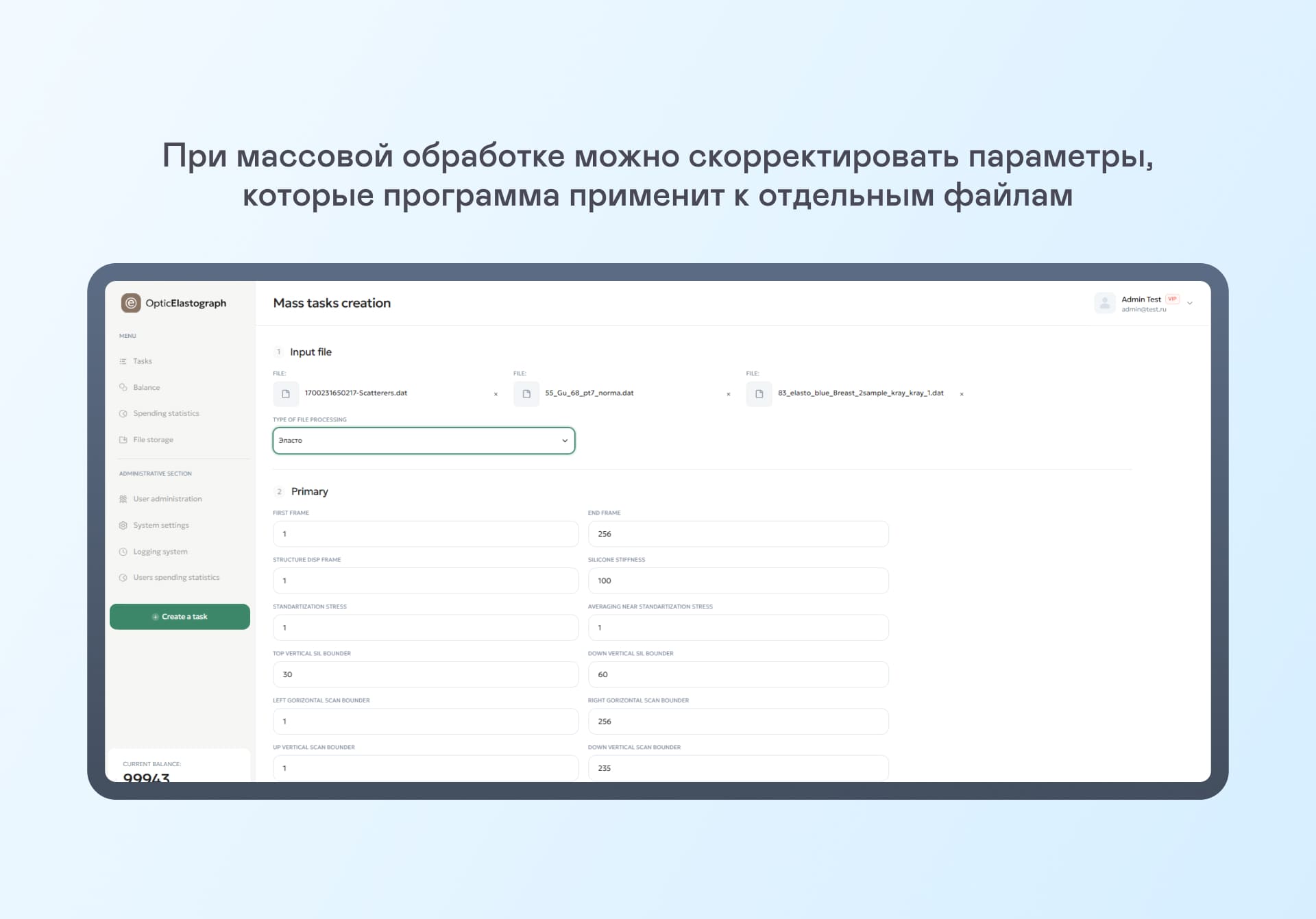
Для тяжеловесных файлов вы предусмотрели загрузку через S3-хранилище, чтобы не загружать их через веб-интерфейс. Это решение упрощает передачу данных и позволяет обрабатывать большие объемы без ограничений.
Кому актуально это решение
Решение подходит компаниям, которые обрабатывают большие объемы данных и запускают ресурсоемкие вычисления:
- компаниям в области анализа данных и ML;
- инженерным и расчетным подразделениям;
- научным и исследовательским организациям;
- компаниям с задачами пакетной обработки файлов.



Обсудить проект
Расскажите о проекте в форме или свяжитесь с нами напрямую
Написать нам на почту
Написать нашему аккаунт-директору в Telegram
Московский офис
Новая площадь, 6