
ML-система прогнозирования спроса для лидера в производстве упаковки
Внедрили систему машинного обучения с показателем 10% по шкале MAPE. Помогли предугадать спрос, ускорить оборот продукции и оптимизировать остаток на складе.
Проблема — нестабильность спроса
Крупным производственным компаниям приходится работать в условиях непредсказуемого спроса. Заказчики могут месяцами ничего не заказывать, а потом внезапно запросить огромную партию. В итоге производство то простаивает, то заваливает склады готовой продукцией, срочно закупает сырье по высоким ценам, берет кредиты и теряет маржу.
В 2024 году Riverstart решали эту проблему для одного из лидеров рынка производства пластиковой упаковки для пищевой промышленности (NDA). Компания обеспечивает упаковкой крупнейшие FMCG-бренды России.
Задача — найти способ прогнозировать заказы, чтобы планировать закупки сырья и оптимизировать складские запасы.
Решение: система прогнозирования спроса на базе ML
Riverstart разработали ML‑систему, которая прогнозирует спрос. Показатель средней абсолютной ошибки модели прогнозирования составляет 10% по шкале MAPE (Mean Absolute Percentage Error). Это значит, что в среднем прогноз отклоняется от реальных значений на 10%.
Мы собрали и проанализировали исторические данные по заказам за несколько лет, включая сезонные колебания и дополнительные факторы, влияющие на спрос. Модель обучили на этих данных и провели три этапа тестирования, в ходе которых клиент смог составить впечатление о пользе технологии для своего бизнеса. До внедрения системы машинного обучения компания несла потери из-за излишков сырья на складе или наоборот, его недостатка. После внедрения получилось существенно сократить эти потери и избежать ненужных расходов.
Доработка и развитие модели привело к тому, что она выдает прогнозы и обновляет их в динамическом режиме. Это позволяет компании заранее готовиться к скачкам спроса: планировать производство, управлять закупками и избегать избыточных запасов или авральных закупок.
Клиент поделился собственными данными: экономия за месяц составила около 1,5-2 миллиона рублей за счет того, что он может:
- предварительно планировать закупки сырья на основе прогнозов;
- отказаться от срочных кредитов на внеплановые закупки сырья под большие проценты;
- оптимизировать запасы товаров на складе, избегая дополнительных расходов на обслуживание и хранение.
Почему ML: как мы оценивали классические методы прогнозирования и искали решение
В классические методы прогнозирования обычно входит Excel-анализ, линейные модели и простая аналитика исторических данных. При резких скачках спроса такая аналитика неэффективна: она не справляется с динамикой заказов, в ней не учитываются резкие скачки спроса, изменения цен на сырье, сезонные колебания и внешние факторы, которые происходят в реальном времени.
Модель прогнозирования на основе ML обрабатывает большие массивы данных, находит скрытые зависимости, точнее предсказывает неожиданные изменения спроса. Это помогает бизнесу готовиться к крупным заказам заранее и без лишних затрат.
Модель машинного обучения, которую мы создали, может:
- выявлять сложные нелинейные взаимосвязи и обучаться на новых данных;
- анализировать внутренние и внешние факторы: историю заказов, колебания курсов валют, действия конкурентов, сезонность;
- выявлять из параметров ключевые для прогнозирования;
- автоматически адаптироваться к изменениям без ручной переоценки факторов.
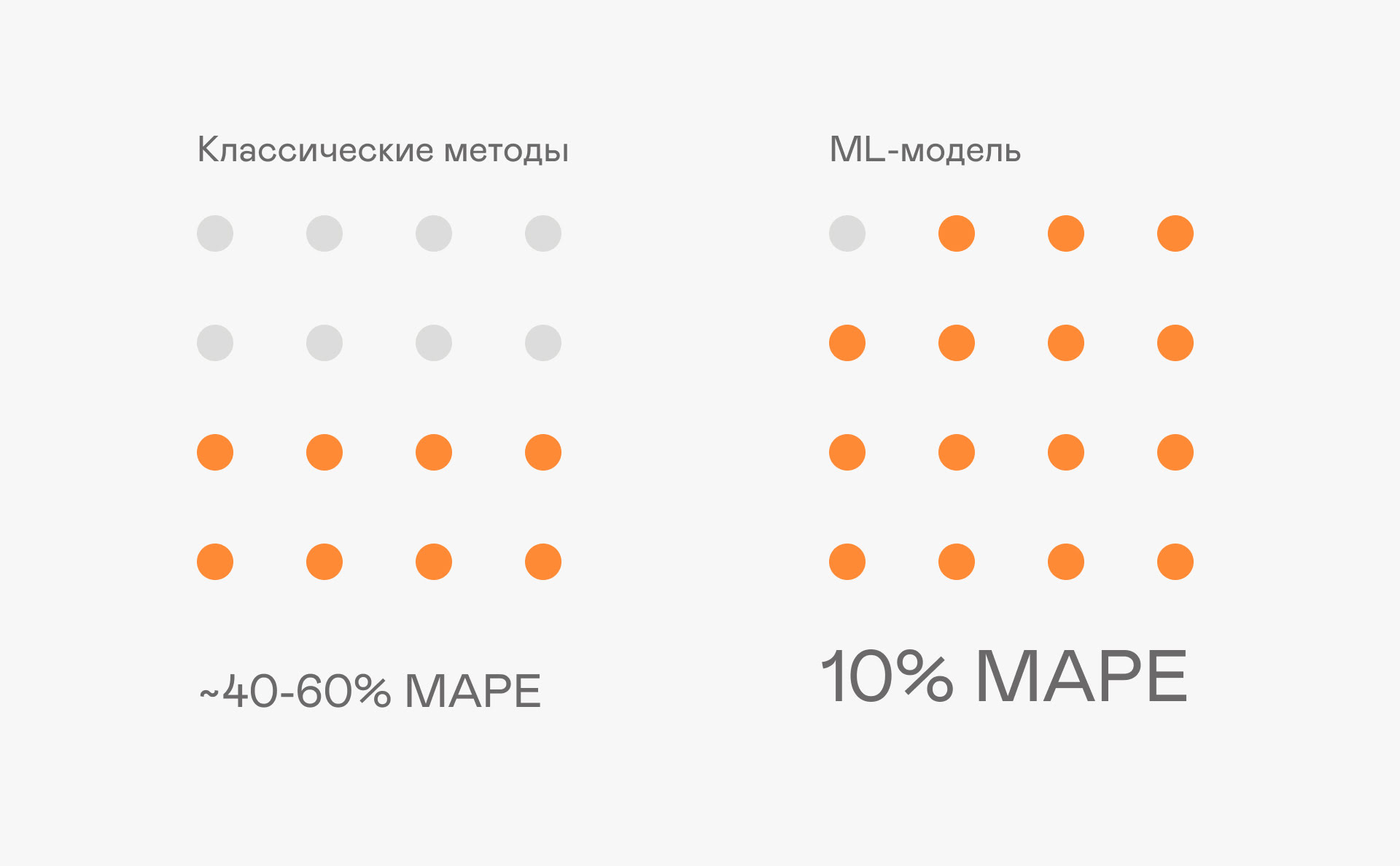
Точность классических методов — 40–60%, что недопустимо для бизнеса. Прогнозирование с помощью ML-модели дает 10 MAPE (Mean Absolute Percentage Error). Это показатель средней абсолютной процентной ошибки, который измеряет точность прогноза в процентах. В среднем, прогноз отклоняется от реальных значений на 10%.
Для бизнеса 10% MAPE означает, что прогноз отклоняется от реальных значений на 10%: при прогнозе заказа на 1 млн единиц реальный спрос будет в пределах 900 000 –1 100 000 единиц продукции. Такой уровень точности позволяет уверенно планировать закупки и производство.
Мы разделили внедрение ML-системы на несколько ключевых этапов, чтобы минимизировать риски для бизнеса и доказать эффективность решения.
1. Анализ и очистка данных для обработки: больше 30% SKU имели «рваные» данные
Мы обработали SKU (Stock Keeping Units) — исторические данные по каждому заказу и каталожному номеру. Больше 30% оказались с большим количеством пропусков или неполными записями. Это проблема, поскольку качество информации напрямую влияет на точность модели прогнозирования спроса.
Мы изучили отчеты, построили графики распределения цен и нашли ошибку: сотрудники клиента указали часть данных с учетом НДС, а часть — без него. Такие несоответствия приводят к искажению прогноза.
Перед созданием ML‑системы мы наводим порядок в данных, чтобы привести их в единому формату и устранить ошибки. Это позволяет системе обучаться на реальных кейсах и становится основой для прогнозов. Ошибки исправили, ML-модель получила качественную базу.

2. Разработка и тесты системы прогнозирования на ML
Мы поэтапно проверили работу модели, чтобы клиент мог оценить ее пользу и надежность:
- Демо-тестирование. Цель — показать клиенту работу модели, чтобы он мог осознать, полезна ли технология для его бизнеса и насколько. В течение месяца клиент наблюдал за демоверсией модели: система обрабатывала текущие данные и показывала прогнозы в тестовом режиме.
- «Слепые» тексты на прошедших годах. Мы загрузили данные за 2018–2022 годы и попросили модель предсказать спрос за 2023‑й, а потом сравнили прогнозы с реальными цифрами. Результат впечатлил — точность модели составила 90%, погрешность 10%.
- Стресс-тесты. Мы искусственно создавали рыночные аномалии и добавили новые параметры: погода, праздники, колебания цен на сырье. Система стабильно сохраняла точность в рамках 90%, доказав свою надежность в кризисных сценариях.
Эти тесты стали решающим аргументом для клиента — после них компания утвердила полномасштабное внедрение системы.

3. Доступ к ML-системе — 4 варианта интеграции ML в бизнес
Мы предложили несколько вариантов интеграции ML-системы, каждый из которых решал конкретные бизнес-задачи:
- Самостоятельная работа с SaaS-решением. Клиент самостоятельно загружает данные в облачную систему через Excel и получает прогнозы. Это позволит быстро запустить процесс без сложных интеграций и с минимальными затратами.
- On‑premises версия. Мы разворачиваем систему на серверах клиента, интегрируем с его внутренними системами и настраиваем. Клиенту не нужно вручную загружать данные, он получает прогнозы когда угодно по клику.
- Анализ силами Riverstart. Если у клиента нет ресурсов на подготовку данных, мы берем это на себя: очищаем «сырые» данные, загружаем их и предоставляем готовые прогнозы.
- Глубокая интеграция. Подключаемся к внутренним системам компании (например, 1С) через защищенный доступ и выполняем полный цикл — от извлечения данных до предоставления прогноза без участия клиента.
Выбор варианта зависит от масштабов бизнеса, ИТ-инфраструктуры и готовности к изменениям. Наш клиент использует SaaS-решение, однако в будущем планирует перейти на On-premises версию.

ML-система помогает избежать непредсказуемых расходов
Главное достижение интеграции ML-системы — стабильные операционные процессы, благодаря которым компания реже сталкивается с непредсказуемостью.
Раньше компания ежемесячно теряла деньги на экстренных закупках, кредитах и хранении избыточных запасов, а теперь на нее работает отлаженный механизм прогнозирования. Сезонность перестала быть кризисным фактором: система предсказывает пики и спады спроса, учитывая десятки параметров — от цен на сырье до активности ключевых клиентов.
В результате мы внедрили ML-систему прогнозирования, которая:
- сэкономила около 2 млн руб. за месяц;
- снизила складские запасы без риска дефицита;
- избавила от внезапности в заказах и необходимости в экстренных кредитах.
Машинное обучение стало стратегическим инструментом управления производством и финансами компании. Сейчас компания использует формат SaaS-решения: загружает данные своими силами и получает результаты. В планах переход на on-premises версию для большей автономности и контроля над данными.

Внедрили ML-систему, прогноз которой может отклоняться от реальных значений всего на 10%




Обсудить проект
Расскажите о проекте в форме или свяжитесь с нами напрямую
Написать нам на почту
Написать нашему аккаунт-директору в Telegram
Московский офис
Новая площадь, 6