
ML-сервис прогнозирования спроса для FMCG-компании
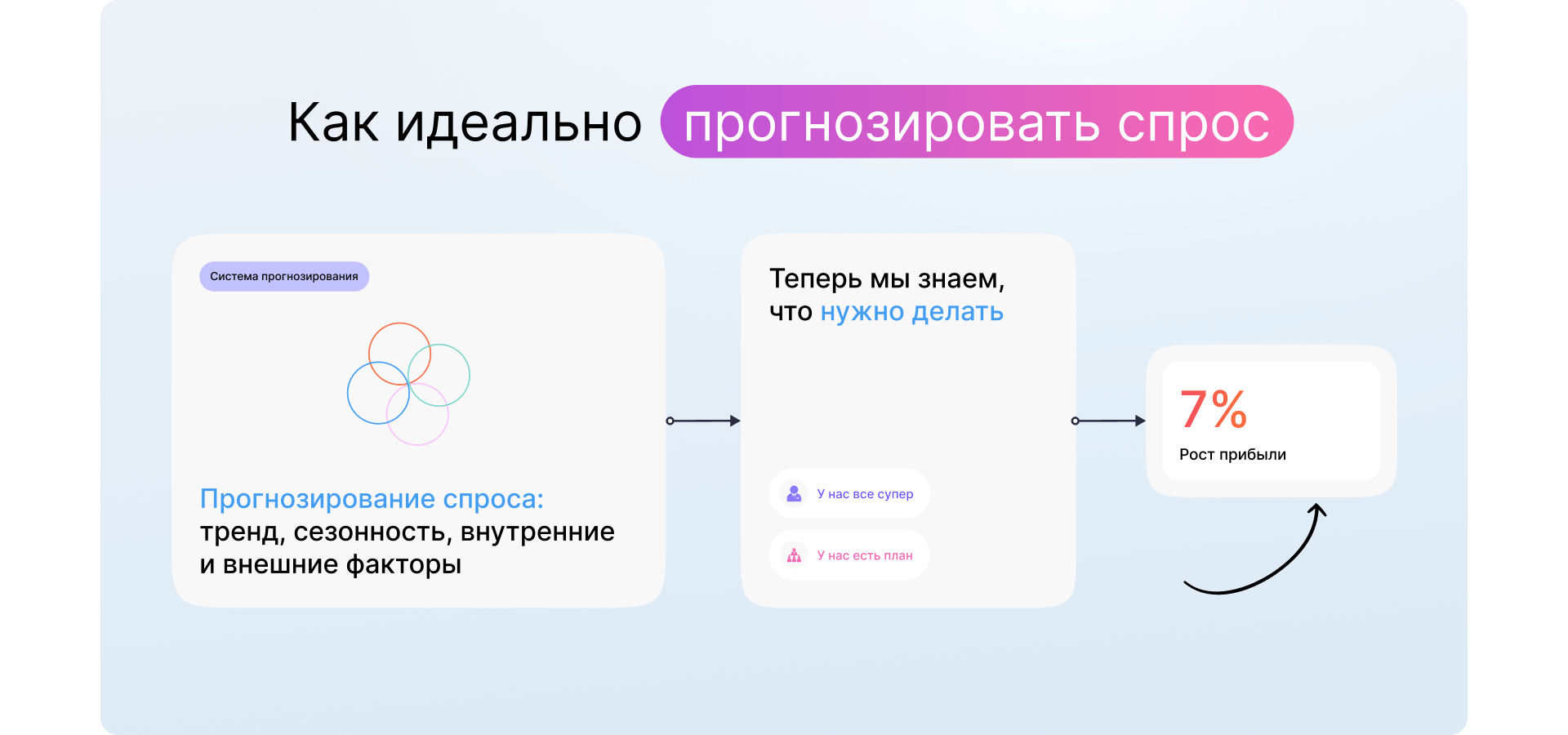
Разработали ML-модель прогнозирования спроса, благодаря которой выручка международной компании увеличилась на 2%, а прибыльность маркетинга на 7%.
Кратко о проекте
Мы разработали ML-модель прогнозирования спроса для сырьевой компании — название не разглашается по условиям NDA. Модель с помощью AI помогает рассчитать, какое количество товаров, каких торговых марок, когда и где нужно продавать, чтобы выполнять квартальные и годовые планы магазинов по розничному товарообороту (РТО) и маржинальности.
Мы помогли клиенту:
- собрать исторические данные о продажах в магазинах;
- обнаружить и устранить методологические ошибки в сборе данных;
- выявить закономерности спроса.
На основе этих данных мы за 14 недель разработали и обучили ML-модель и запустили сервис. Он уже помог повысить эффективность сбыта.

Клиент занимается производством и сбытом FMCG-товаров
Российское представительство одной из крупнейших транснациональных корпораций с несколькими филиалами в стране. В разные годы под разными позициями входило в десятку крупнейших компаний с иностранным участием в России.
Компания производит и реализует в России товары нескольких торговых марок. Чтобы продавать товары в разных регионах страны, компания должна заранее — за год, полугодие, квартал — договариваться о производстве, поставках и строить распределительные центры. Для этого ей нужно знать, какое количество товара, в какой точке, в какое время и по какой цене должно храниться и продаваться.
Чтобы определить эти параметры, компания прогнозирует этот самый спрос — в отдельности по каждому товару, товарной группе, полке, магазину, региону, городу.

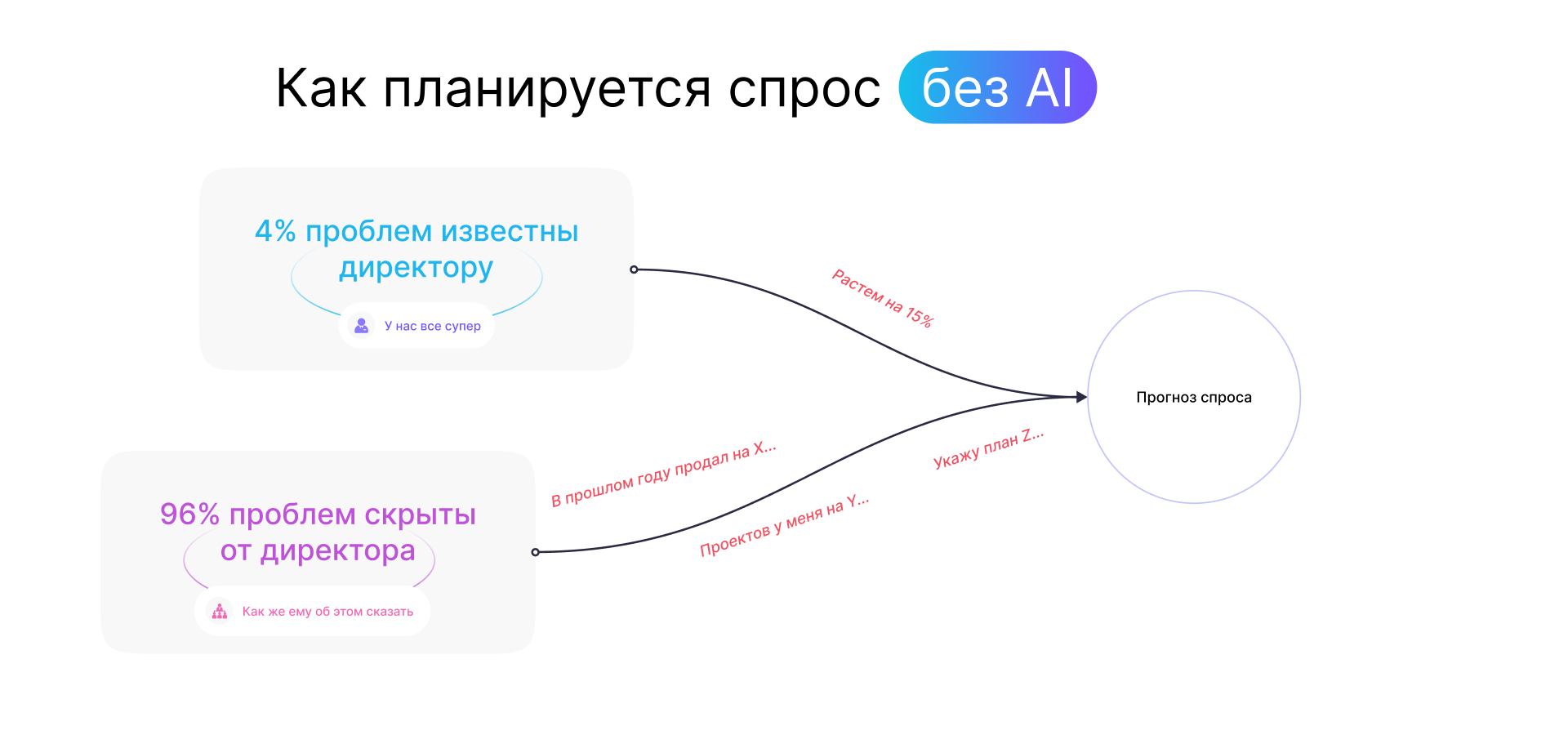
Проблема — менеджеры подгоняют планы, чтобы достичь KPI
Сначала компания использовала для прогнозирования спроса Excel-таблицы, затем перешла на систему коммерческого планирования Anaplan.
Однако региональные менеджеры подгоняли плановые данные по продажам так, чтобы точно их достичь и выполнить свои личные KPI. Например, они могли просить дополнительные скидки на товары и использовать маркетинговый бюджет — в результате объемы продаж быстро росли, но выручка и прибыль росли незначительно.
В итоге розничная точка выполняла поставленный план, но не раскрывала весь экономический потенциал, а в некоторых случаях показывала регресс в сравнении с аналогичным периодом в прошлом — по целому магазину и отдельным продуктовым группам.
Результат: руководство получало искаженную отчетность на разных уровнях — на уровне страны, региона, округа, отдельного города и просто магазина.
Когда наступил период насыщения рынка, руководство компании сконцентрировалось на эффективности бизнеса и решило взять такие ситуации под контроль. Они хотели развить идею принятия решений на основе данных, при этом устранить существовавшие пробелы и намеренные искажения. Для этого нужно было научиться строго и непредвзято контролировать показатели повсеместно.
Задача — разработать систему предиктивной аналитики на основе ML
Расскажем, как устроена модель прогнозирования на основе машинного обучения, когда нужно внедрять ее в бизнесе и что для этого требуется.
Готовые коробочные решения не подходили клиенту, потому что точность их прогнозирования не соответствовала стандартам головного офиса, а затраты на их доработку оказались выше затрат на разработку собственного решения. Клиенту нужна система с участием AI, которая позволит указывать KPI на всех уровнях управления и будет прогнозировать спрос и предложение необходимые для выполнения заданных показателей.
Задача: разработать ML-модель, чтобы определять, сколько товаров, каких торговых марок, когда и где продавать, чтобы выполнять квартальные и годовые планы магазинов по розничному товарообороту (РТО) и маржинальности.
Кроме разработки самой ML-модели мы помогли собрать и проанализировать данные, выявить закономерности и определить какие факторы влияют на спрос и результаты прогноза. А также провели интеграцию с существующей системой коммерческого планирования, чтобы менеджеры по логистике начали планировать складские запасы на основе полученных прогнозов.
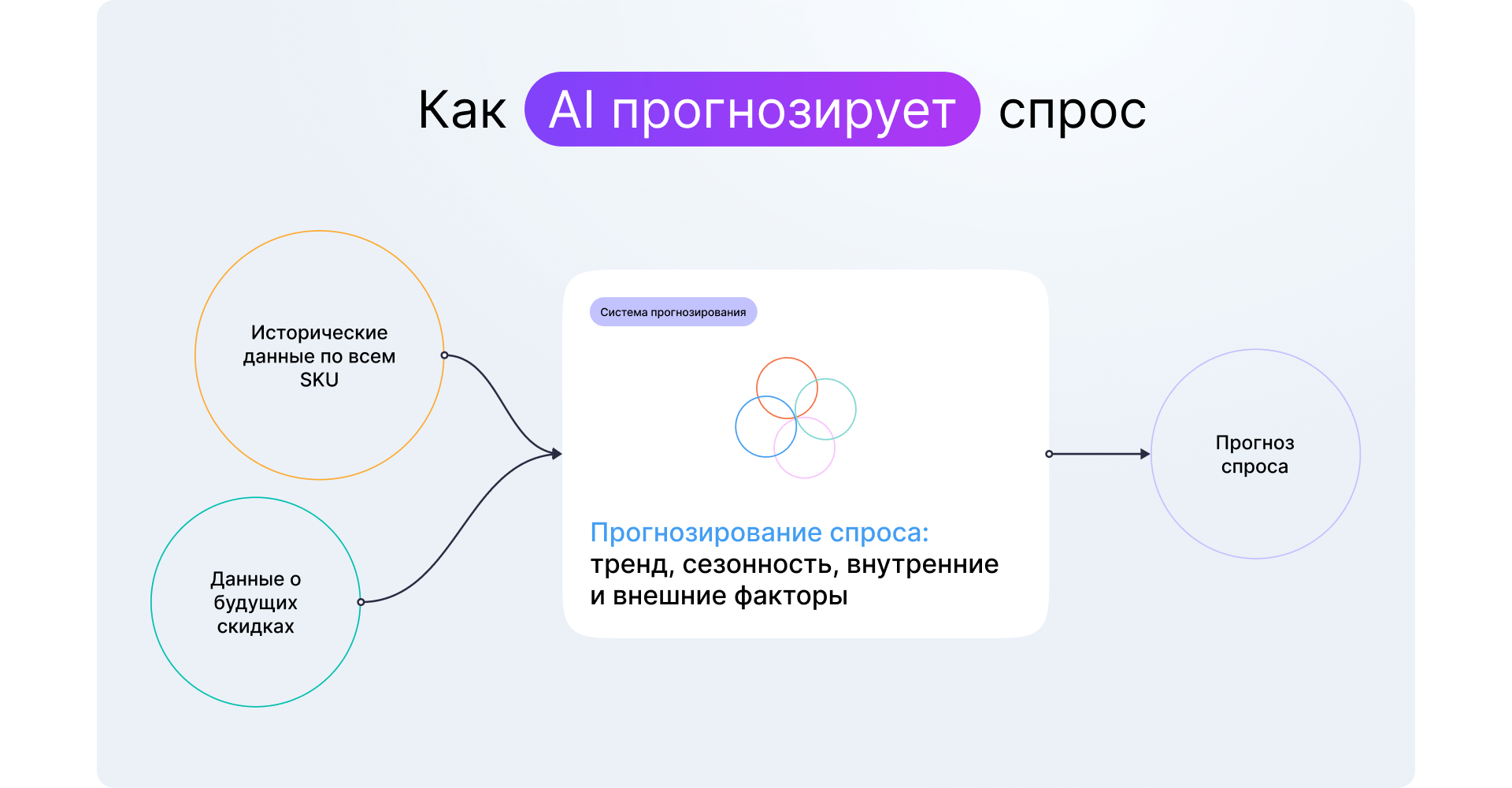
Принцип работы системы прогнозирования
1. Этап подготовки
Аналитики собирают исторические данные по сетям минимум за 3,5 года, чтобы получить информацию о сезонности продаж.
2. Параметры для прогноза
Менеджер указывает параметры прогноза: период для построения модели, необходимую разбивку прогноза по дням, неделям или месяцам, указывает промоакции, планируемые скидки или повышения цены.
3. Анализ данных
Программа анализирует продажи и скидки за такой же период в прошлые годы и учитывает другие факторы, влияющие на спрос — наличие товаров на складах, изменения цен по прайсу, разные тренды, эффекты сезонности, гало и другие.
4. Отчет с прогнозом
На основе загруженных данных программа составляет отчет. В нем менеджер видит, какие товары, в каком количестве, в каких магазинах и по каким ценам ему нужно выставить, чтобы его город достиг заданных целевых показателей. Другими словами, менеджер получает руководство по тому, как превратить плановый показатель в фактический.
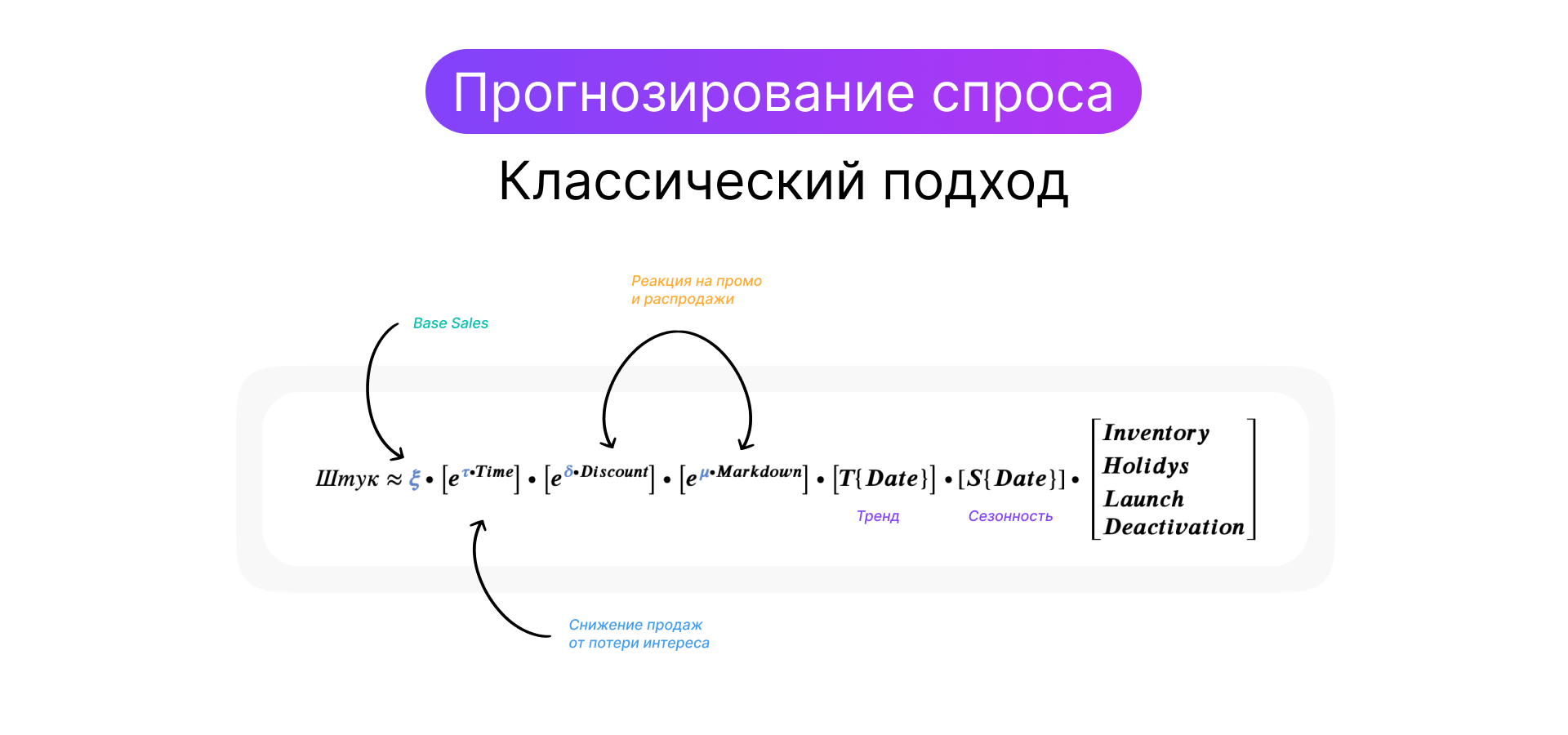
Как устроена система технически
Модель использует исторические данные по продажам, которые максимально подробно описывают динамику спроса в прошлом. Дополнительно формируется ряд признаков. Этот набор подается на вход модели машинного обучения. В ходе обучения модель извлекает закономерности между признаками и спросом. На основе этих закономерностей дальше формируется прогноз спроса.
Какие данные требуются, чтобы разработать похожую систему
Мы делали программы моделирования спроса для компаний из разных отраслей: для дистрибьютора химических материалов, для производителя керамической плитки, для магазина одежды, для дистрибьютора рыбы. Практическим путем мы сформировали набор требований для бизнеса, который хочет внедрить подобную модель прогнозирования.
Требования и критерии
1. Должны быть исторические данные по продажам
Например, подойдет ряд данных «Локация — ID товара — Дата продажи — Количество проданных единиц товара». Этого уже достаточно для того, чтобы построить первый прогноз.
2. Истории данных должно хватать для запрашиваемого периода прогнозирования
Если необходимо спрогнозировать спрос на три месяца, то компания должна собрать и предоставить данные как минимум за два предшествующих года и три месяца. Если в продажам свойственна сезонность, то нужно иметь данные за три-четыре предшествующих года.
3. Для более высокой точности прогнозирования нужны дополнительные параметры
Уточнить прогноз спроса можно, если добавить в него следующие данные: информацию о складских остатках, цены товаров, промо активности. Добавлять данные, как и повышать точность прогноза, можно постепенно.
4. Нужно учитывать степень дисперсии данных
Иногда ежедневные данные сильно отличаются друг от друга. Например, на основании данных кажется, что каждые три дня происходит всплеск продаж, превышая норму в 10 раз. Такое может случаться, если данные в систему учета загружают, когда придется и сразу пачкой. Либо дистрибьютор закупает крупные партии и не делится информацией о ежедневных продажах.
5. Нужно избавиться от нулей и пропусков в данных
Для идеального прогнозирования в данных о продажах не должно быть пропусков. Сложно моделировать спрос, если приходится работать с нулевыми значениями. Это снижает точность прогноза, при этом сложно точно определить из-за чего упала точность — из-за ошибки искусственного интеллекта при расчетах или из-за большого количества дней с нулевыми продажами в данных.
Сбор и подготовка данных — это целое направление в науке о данных. Если на стороне клиента нет команды или специалиста по данным, то мы помогаем собирать и обрабатывать данные перед тем, как загружать их в модель и начинать обучение.
Нашли и исправили проблемы и неточности сбора данных
- Работали с живыми данными
- Прогнозировали спрос с учетом цен, скидок и каннибализации товаров
- Рассчитывали оптимальные параметры для скидок
У клиента не было какой-то единой и строгой системы сбора данных, поэтому могли быть ошибки, пропуски, проблемы со сбором. При анализе данных и обучении модели, мы должны были преодолеть эти проблемы, при этом не увязнуть в процессе, но и добиться необходимой точности прогноза.
Мы искали не просто неправильные показатели продаж, цены и спроса. Мы искали методологические ошибки сбора и очищали данные от них. Например, изучили статистические отчеты и графики распределения цен, нашли аномальные распределения, залезли в таблицы с цифрами и обнаружили, что часть стоимостей заносились с учетом НДС, а другие — нет.
Когда самописная модель превосходит коробочное решение
На основании наших кейсов можем сказать, что бизнес начинает разрабатывать собственную модель и отказывается от коробочных решений по типу SAS, AWS, Google Analytics и других, когда:
- собирается развивать направление работы с данными внутри компании и внедрять их в новых вертикалях;
- хочет сохранять дата-экспертизу внутри, чтобы развивать модели и оценивать влияние дополнительных параметров на прогнозные значения спроса;
- дорабатывать систему под свои задачи;
- хочет иметь сверхточный прогноз.
В таких случаях готовые коробочные решения не подходят из-за низкой точности прогнозирования.
Коробочные решения пытаются уместить в себе специфику разных отраслей, разных бизнесов, разных влияющих факторов. То, что подходит для продажи свежей рыбы, плохо работает для дистрибуции, например, керамической плитки.
В результате компании не могут вписать свои требования и данные в жесткие рамки коробочного решения, а донастройка решения под свои задачи и стандарты обходится дороже разработки собственной модели.
Как клиент поддерживает и развивает систему
Модель, как и сам бизнес, можно представить как живой организм. Чтобы она продолжала работать и показывать высокую точность прогнозирования, нужно ее постоянно обучать и докручивать под новые обстоятельства. Например, бизнес начинает собирать новые данные о продажах и хочет учитывать их влияние на прогноз. В этом случае нужна инженерная команда, которая понимает принцип работы текущей модели и сможет ее доработать, донастроить и дообучить. Это может быть инхаус-команда на стороне бизнеса или постоянный технический партнер — все зависит от обстоятельств.

Сделали ML-сервис прогнозирования товарного спроса




Обсудить проект
Расскажите о проекте в форме или свяжитесь с нами напрямую
Написать нам на почту
Написать нашему аккаунт-директору в Telegram
Московский офис
Новая площадь, 6